
Le fichier robots.txt est un fichier texte que l’on place à la racine d’un site web. Son rôle est simple mais stratégique : il donne des instructions aux robots d’exploration (user-agent) comme Googlebot pour leur indiquer quelles parties du site ils peuvent explorer et lesquelles ils ne doivent pas explorer (pour des raisons SEO ou de sécurité).
C’est un élément clé en SEO et surtout de la sécurité du site web, souvent oublié. Mais qui joue un vrai rôle pour la gestion de ton site web et la visibilité de ton domaine dans les résultats de recherche Google. C’est en quelque sorte le premier guide que les robots d’exploration (ou crawlers) vont consulter avant de parcourir ton site internet.
Le fichier robots.txt est toujours situé à un emplacement bien précis : à la racine du domaine de ton site web, et il doit impérativement porter ce nom exact : robots.txt.
C’est là que les moteurs de recherche comme Google ou Bing vont automatiquement le chercher lorsqu’ils commencent à explorer ton site.
Peu importe que ton site tourne sous WordPress ou une autre solution, le principe est le même : le fichier robots.txt doit être directement accessible à cette adresse :
robots.txt : https:// domaine.com/robots.txtLes fonctions clés du fichier robots.txt
Le fichier robots.txt joue un rôle stratégique en SEO. Il te permet de donner des directives précises aux moteurs de recherche sur l’exploration de ton site web, mais aussi de restreindre l’accès à certaines zones sensibles pour des raisons de sécurité.
Voici les principaux usages du fichier robots.txt :
1. Bloquer l’accès à certaines pages ou répertoires
Tu peux interdire l’exploration de pages sensibles, de fichiers HTML inutiles, ou de répertoires techniques (comme les dossiers d’administration ou les fichiers internes .php).
Par exemple, pour empêcher l’accès à l’URL de connexion admin de WordPress (comme www.domaine.com/wp-admin/), il suffit d’ajouter cette directive dans le fichier robots.txt :
Disallow: /wp-admin/2. Optimiser le budget de crawl
Le budget de crawl correspond au temps et aux ressources que les robots d’exploration de Google allouent à l’exploration de ton site. En bloquant les ressources inutiles (comme certains fichiers ou répertoires techniques), tu les aides à se concentrer sur les pages vraiment utiles pour ton référencement naturel.
3. Empêcher l’indexation de contenus non stratégiques
Certaines pages n’ont pas vocation à apparaître dans les résultats de recherche (ex : panier, filtres de recherche, admin…). Le fichier robots.txt te permet de les stopper proprement.
4. Protéger ton site contre certains robots malveillants
Le fichier robots.txt ne sert pas qu’au SEO : il peut aussi participer à la sécurité de ton site. En plus des robots officiels comme Googlebot, Bingbot ou DuckDuckBot, il existe des robots malveillants qui se font passer pour des bots SEO, mais qui ont pour but de détecter des failles ou de lancer des attaques.
Même si le fichier robots.txt ne peut pas bloquer techniquement un robot malveillant (car rien ne l’oblige à respecter les règles), il permet tout de même de cacher certaines zones sensibles (admin, scripts, fichiers internes) aux robots les plus respectueux.
Pour aller plus loin dans la sécurité, pense aussi à combiner ton fichier robots.txt avec des règles côté serveur (fichiers .htaccess, pare-feu applicatif, etc.).
5. Indiquer le chemin du sitemap
Le fichier robots.txt est aussi l’endroit idéal pour indiquer aux moteurs de recherche où trouver ton fichier sitemap XML (le plan de ton site).
Sitemap: https://www.domaine.com/sitemap.xmlContrairement au fichier robots.txt qui doit toujours porter ce nom exact, un sitemap XML peut avoir un nom personnalisé comme sitemap_index.xml, product-sitemap.xml, page-sitemap.xml, etc.
L’important, c’est d’indiquer le bon chemin dans ton robots.txt
Comment fonctionne le fichier robots.txt ?
Le fichier robots.txt fonctionne avec un ensemble de directives simples, en texte brut, que les moteurs de recherche comprennent très bien. Ces instructions sont lues ligne par ligne par les robots d’exploration, qui adaptent ensuite leur comportement en fonction.
Voici les principales règles que tu peux utiliser :
| Directive | Fonction |
|---|---|
| User-agent | Permet de cibler un robot spécifique. Exemple : Googlebot, Bingbot, ou * pour tous les robots. |
| Disallow | Sert à verrouiller l’accès à une page, un fichier ou un répertoire précis. |
| Allow | Autorise explicitement l’exploration d’une ressource, même si le dossier parent est bloqué. |
| Sitemap | Indique le chemin du fichier sitemap.xml, pour aider les moteurs à mieux comprendre la structure de ton site. |
| Noindex | Demande aux moteurs de ne pas indexer une page, même si elle est accessible au crawl. Attention : cette directive ne fonctionne pas dans le fichier robots.txt pour Google. Elle doit être utilisée en balise meta HTML ou dans l’en-tête HTTP. |
Ces directives permettent de contrôler finement ce que les moteurs peuvent explorer ou non sur ton site.
Exemple de fichier robots.txt basique
Voici à quoi peut ressembler un fichier robots.txt simple et efficace :
User-agent: *
Disallow: /admin/
Disallow: /wp-content/plugins/
Allow: /wp-content/uploads/
Sitemap: https://www.example.com/sitemap.xmlExplications :
- User-agent: * : Cette directive s’applique à tous les robots des moteurs de recherche (Googlebot, Bingbot, etc.)
- Disallow: /admin/ : On interdit l’exploration du répertoire /admin/
- Disallow: /wp-content/plugins/ : On bloque aussi le dossier des plugins (souvent inutile à indexer)
- Allow: /wp-content/uploads/ : En revanche, on autorise l’exploration des images ou fichiers stockés dans /uploads/ (important pour le SEO image)
- Sitemap: : On indique l’URL du fichier sitemap.xml pour faciliter l’exploration et l’indexation des pages importantes du site
Meilleures pratiques SEO pour ton fichier robots.txt
Mal configuré, un fichier robots.txt peut nuire à ton référencement naturel. Voici les bonnes pratiques à suivre pour éviter les erreurs et tirer le meilleur de ce petit fichier stratégique :
1. Autorise les ressources essentielles
Ne bloque jamais les fichiers nécessaires à l’affichage de ton site web, comme le CSS, le JavaScript ou les images. Google doit pouvoir les explorer pour bien comprendre ton contenu et la structure de tes pages.
2. Bloque les pages sans valeur SEO
Tu peux bloquer l’accès aux espaces techniques ou aux pages sans intérêt pour les moteurs :
- Panier
- Compte client
- Admin / back-office
- Pages de test ou en double
- Les URL avec les filtres de recherche
- Les URL de recherche
3. Indique ton sitemap
Ajoute toujours la directive Sitemap dans ton fichier robots.txt pour guider les robots vers la bonne version de ton plan de site. Ça facilite l’exploration et l’indexation de tes pages importantes.
Et côté sécurité ? Mentionner explicitement ton sitemap ici permet d’éviter que des robots non désirés le cherchent ailleurs, ou scannent inutilement d’autres dossiers de ton site.
C’est une petite précaution, mais elle limite l’exposition inutile de certaines parties du site.
4. Ne bloque jamais par erreur des pages stratégiques
Avant de publier ou modifier ton fichier, vérifie qu’aucune page clé n’est bloquée (accueil, articles, pages produits…). Une simple ligne mal placée peut faire disparaître ton contenu des résultats de recherche.
5. Bien faire la différence : Disallow ≠ Noindex
- Disallow : empêche l’exploration d’une page ou d’un répertoire (à mettre dans le robots.txt)
- Noindex : empêche l’indexation d’une page (à mettre dans la balise meta de la page, pas dans le fichier robots.txt)
6. Éviter de bloquer tout ton site par erreur
Exemple à ne surtout pas reproduire :
User-agent: *
Disallow: /Avec cette directive, tu interdis aux moteurs de recherche d’explorer l’intégralité de ton site web.
Résultat : plus aucune page n’est visible dans Google.
Comment tester son fichier robots.txt ?
Avant d’aller plus loin, commence par vérifier que ton fichier robots.txt est bien en ligne.
Pour ça, rends-toi sur www.tondomaine.com/robots.txt.
Si le fichier s’affiche correctement dans ton navigateur, c’est bon signe : il est bien présent.
Ensuite, tu peux utiliser des outils pour tester si son contenu est correct, et s’il ne bloque pas des pages importantes par erreur :
1. Google Search Console
Utilise l’outil d’inspection d’URL pour vérifier si une page est bloquée par ton fichier robots.txt. C’est rapide, fiable, et directement intégré à ton compte Search Console.
2. L’outil de test robots.txt de Google
➡️ Accéder au testeur officiel
Tu peux coller le contenu de ton fichier, simuler des requêtes et voir quelles pages sont autorisées ou bloquées selon les directives.
3. Les outils SEO comme Semrush ou Ahrefs
Ces plateformes proposent des fonctions d’analyse plus avancées, idéales pour vérifier l’exploration globale de ton site, détecter des erreurs de configuration, et ajuster sa stratégie SEO si besoin.
Comment créer un fichier robots.txt sous WordPress ?
Il existe deux façons simples de créer et gérer ton fichier robots.txt sous WordPress.
1. Créer ton fichier manuellement
Voici les étapes :
- Accède à la racine de ton site via ton hébergeur (en FTP ou via ton espace client).
- Crée un nouveau fichier texte et nomme-le exactement robots.txt.
- Rédige tes directives SEO à l’intérieur (User-agent, Disallow, Allow, Sitemap…).
- Enregistre et mets le fichier en ligne à la racine de ton domaine.
2. Utiliser un plugin SEO WordPress
Si tu utilises un plugin SEO comme Rank Math, Yoast SEO, ou SEOPress, tu peux gérer ton fichier robots.txt directement depuis ton interface WordPress, sans passer par le FTP.
SEOPress propose même un outil très visuel pour gérer les règles du robots.txt. Il suffit de cliquer sur les directives que tu veux ajouter puis de les valider sans toucher au code.
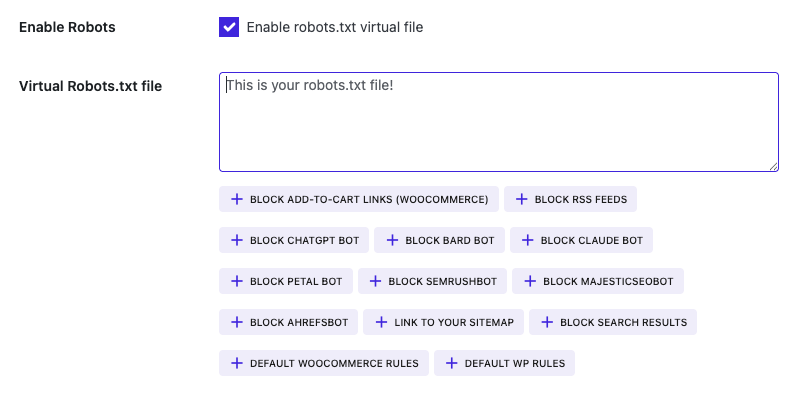
Quelles directives inclure dans un fichier robots.txt WordPress ?
Certaines règles sont particulièrement utiles, voire indispensables, sur WordPress. Elles permettent d’optimiser ton budget de crawl, éviter l’indexation de pages inutiles, et garder ton site propre aux yeux de Google.
Voici les principales directives à connaître :
Directives par défaut à inclure sur tout site WordPress
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php- Disallow /wp-admin/ : empêche l’exploration du back-office WordPress.
- Allow /wp-admin/admin-ajax.php : autorise l’accès au fichier Ajax, souvent utilisé par certains plugins.
Pour les sites e-commerce avec WooCommerce
Disallow: /wp-content/uploads/wc-logs/
Disallow: /wp-content/uploads/woocommerce_transient_files/
Disallow: /wp-content/uploads/woocommerce_uploads/- Ces répertoires techniques n’ont aucun intérêt SEO : ils doivent rester hors du radar de Google.
Bloquer les URL d’ajout au panier
User-agent: *
Disallow: /add-to-cart=- Ces URL sont générées dynamiquement et peuvent créer du contenu dupliqué inutile.
Bloquer les pages de recherche WordPress
User-agent: *
Disallow: /?s=
Disallow: /page/*/?s=
Disallow: /search/- Dans la majorité des cas, les résultats de recherche interne n’apportent pas de valeur SEO. Autant éviter qu’ils soient indexés.
Bloquer l’accès au flux RSS
User-agent: *
Disallow: /feed/
Disallow: */feed
Disallow: */feed$
Disallow: /feed/$
Disallow: /comments/feed
Disallow: /?feed=
Disallow: /wp-feed- Si tu n’utilises pas les flux RSS, tu peux les bloquer pour éviter qu’ils soient explorés inutilement ou spammés par des mauvais robots.
Ajouter le lien vers ton sitemap XML
Sitemap: https://domaine.com/sitemap.xml- Une directive obligatoire, souvent oubliée.
Ce qu’il faut retenir
Le fichier robots.txt fait partie des éléments techniques souvent sous-estimés en SEO… et pourtant, il joue un rôle clé dans la gestion, la visibilité et la sécurité de ton site web.
Bien configuré, il permet :
- De guider les moteurs de recherche comme Google dans l’exploration de ton site
- D’optimiser l’indexation de tes contenus les plus stratégiques
- De protéger certaines pages sensibles ou techniques
- Et de limiter l’accès à des zones critiques, pour éviter que des bots malveillants ne tentent d’y accéder
Mal configuré, en revanche, il peut :
- Bloquer des pages importantes sans que tu t’en rendes compte
- Laisser indexer des contenus sans intérêt pour ton SEO
- Ou pire, ouvrir des accès non désirés à des fichiers techniques ou des répertoires à risque
La bonne approche ?
- Configurer ton fichier robots.txt dès la mise en ligne du site
- Bloquer uniquement ce qui doit l’être (espaces privés, contenus sans valeur SEO, zones techniques)
- Laisser accessibles les ressources nécessaires à l’affichage (CSS, JS, images)
- Indiquer ton sitemap pour guider les robots à trouver la structure de ton site web
- Et surtout, adapter les règles à ton CMS et à ta structure de site pour éviter les failles
Un fichier robots.txt bien pensé, c’est à la fois un outil SEO et un rempart de sécurité. Un petit fichier, mais un gros impact.